
只要會上網,基本上就少不了會遇上標上 CAPTCHA 名號的驗證碼檢驗系統。然而這套系統的運作原理,和背後存在的商業意義,你又知道嗎?CAPTCHA 其實是一個簡寫,它的全名為 Completely Automated Public Turing test to tell Computers and Humans Apart(全自動區分電腦及人類的圖靈測試)。2007 年,改良版的系統 reCAPTCHA 推出,正式將這套驗證碼系統帶入商業世界。
首先,所謂的 Turing Test(圖靈測試)就是這套系統的靈魂,它在 1949 年由電腦科學先驅艾倫圖靈提出,當時他就認為機器可以透過模仿、學習而產生自己的思想,亦即是我們現時說的人工智能。操作方式大致上就是由一名提問者在不知道對方身份的前提下作出提問,再分別由人類和受測試的機器作出回答。圖靈測試的邏輯是機器無法作出具有「人性」的回答,所以提問者可以單憑回答分辨出人類和機器。要哪天提問者再無法分辨出來了,理論上,這部機器就擁有了「思想」。而 CAPTCHA 則是反向運用這個測試,由伺服器作出「機器無法回答」的問題,所以只要答案正確,就能確保目前的用戶是真人。從最簡單的文字驗證碼來作例子,伺服器會將一個文字的圖片進行扭曲、雜訊等處理,令機器無法辯識圖片中的文字,但這些變化都是在人類可以接受的範圍之中,所以人類可以作出正確的答案。
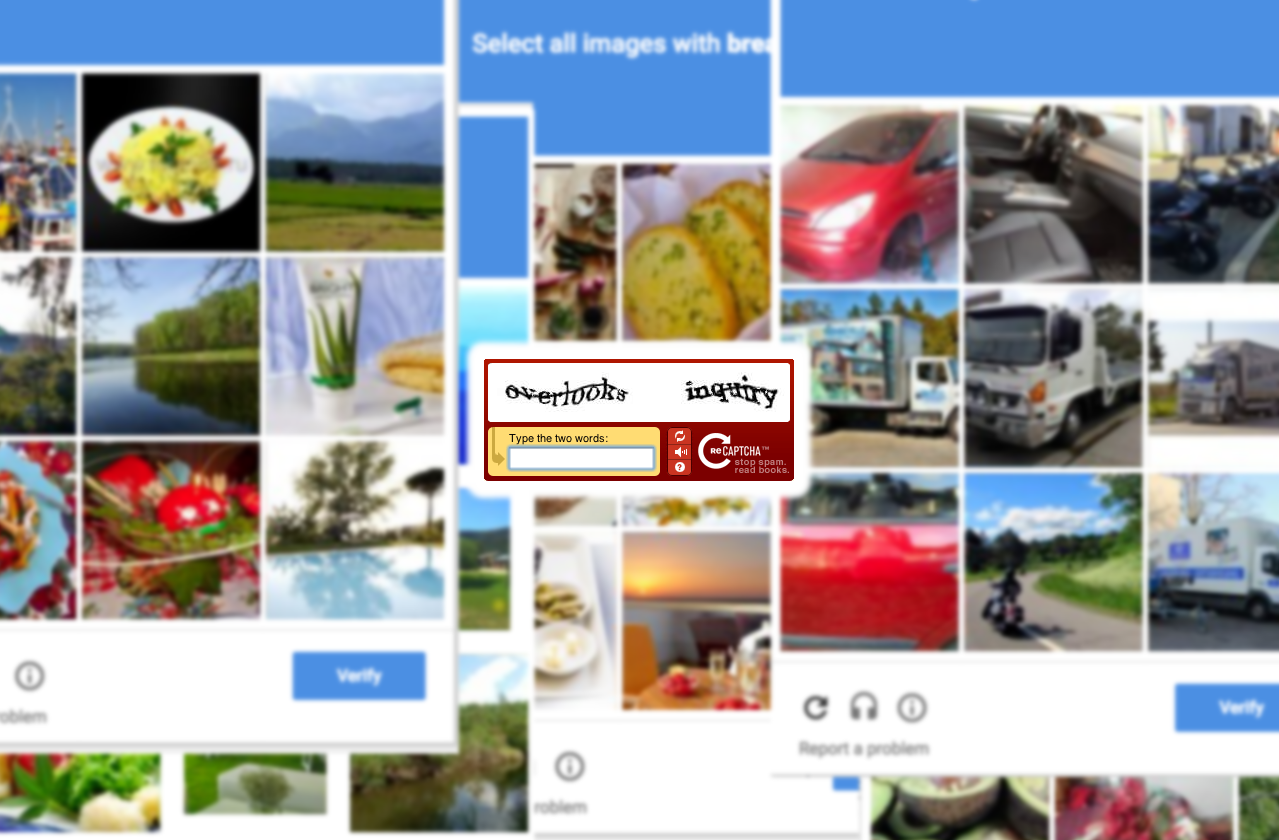
後來,CAPTCHA 的創辦人 Luis von Ahn 教授發現系統說明了人類和機器各有所長,所以就積極開發人機共同工作的 reCAPTCHA 系統。當年的光學識別軟件十分落後,加上書本本身的質素模糊參差,將人類歷史的紙質書本轉化成數碼數據時錯漏百出,毫不可靠。然而想要將人類多年歷史的典籍全部數碼化,所靠的就不能只是一小個工作室的人力物力。故此,reCAPTCHA 系統就為針對這個問題而生。reCAPTCHA 系統通常會有兩組文字,據說其中一段就是本來的驗證用途,而另一段則是一個從書本節錄出來的詞,讓網民在不自覺的情況下幫 reCAPTCHA 的資料庫添寫一筆資料。只要同一個詞在網上被一定數量的網民回答同樣的答案,系統就會默認這個答案是正確的。現時每日有超過 2 億個以上的字符被輸入,等於人類 15 萬小時的工作量。
但這些都只是發展的歷史故事了。現在的人工智能系統再不是使用落後的光學識別軟件,而是利用各種先進的演算法來辨識文字。後來 Google 在 2009 年收購 reCAPTCHA 後利用它龐大的資源不斷強化系統,加上科技如日中天的進化,現時的電腦已經可以比我們分辨更多、更難的文字驗證碼。在 Google 不斷加深扭曲、線條、背景的難度後,人類最終只能回答出 33% 的正確答案,但電腦卻可以正確回答 99%。

而在 Google 接手 reCAPTCHA 的業務後,他們在 2012 年就開始利用了這個系統來優化自家的 Google Map 系統。有時我們會在 reCAPTCHA 上看到只有數字的驗證碼,基本上就是 Google 將路牌的圖片裁寫出來,讓你為他們做義工的痕跡。在現實生活中的門牌、路牌等單靠電腦掃描難以判斷,但交由人類來辨識的話就好辦多了。
從此衍生出來的還有各種各樣的「分類式」驗證,比如讓用家在一堆照片中選出「有車輛」的照片等,其實這些都是在為大數據進行分類工作。換句話說,就是一種訓練人工智能的方式。只要人工智能獲得越來越多的數據量,便可越精準地劃出目標物件的特徵,並在一張全未看過的圖片中找出目標物件。除此之外,還有一種由一張大圖片分割成小圖片的驗證形式,用戶需要在選出含有目標物件的小圖片。通常,目標物件都會是路牌等形狀複雜的物件,而用戶的貢獻就是幫助人工智能勾出目標物件的形狀。

近年網上有一種只需要單點「我不是機器人」的驗證,雖然它實際上沒有讓用戶明確地做了甚麼工作,但事實上卻是訓練人工智能最先進的技術。當我們點選那個方格的時候,網絡便會將我們的資訊,即行為模式、習慣等傳輸到伺服器中,而人工智能便可以透過研究這些數據,學習真人的行為模式。更重要的是,這種技術可以克服了其他既有驗證碼已被人工智能攻破的問題。
綜合報導
Text by Fortune Insight







