
最近,李飛飛團隊的一項研究讓AI可以預測人類的行為,這可能會令自動駕駛等多個領域取得重大的突破。
他們運用一個端到端的多任務學習系統,從畫面中識別人類行為和 TA 與周圍環境的互動情況,然後根據這些信息,預測出這名行人未來的路徑和行為。

此前,AI只能預測人接下來的行走路徑,而無法預測他們將會做什麼。
這項研究,由卡內基梅隆大學(CMU)、Google AI 和史丹佛大學共同完成。
預測行為是建基於預測運動軌跡之上
預測運動軌跡這件事,和預測行為本來就是相輔相成的。
人類走路是以特定目的為導向,瞭解一個人的目的,有助於推測他要去哪。
既然要同步預測運動軌跡和行為,就不能像以往那些研究一樣,把人簡化成一個點了。
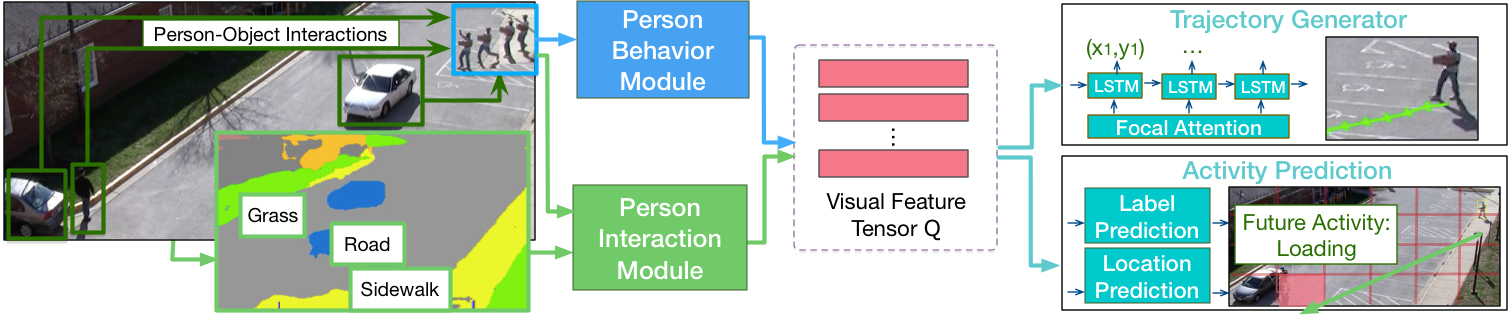
這個神經網路,總共包含 4 部分:
人物行為模塊、人物交互模塊、軌跡生成器、活動預測
其中前兩個模塊是圖像識別的部分,分別負責識別場景中每個人的動作和相互關係。
獲得的信息交給 LSTM 編碼器,壓縮成一個「視覺特徵張量」Q,交給剩下兩部分生成軌跡和活動的預測結果。
人物行為模塊和人物交互模塊
人物行為模塊負責對場景中每個人的圖像信息進行編碼,除了標記人的軌跡點以外,還要對身體活動進行建模。
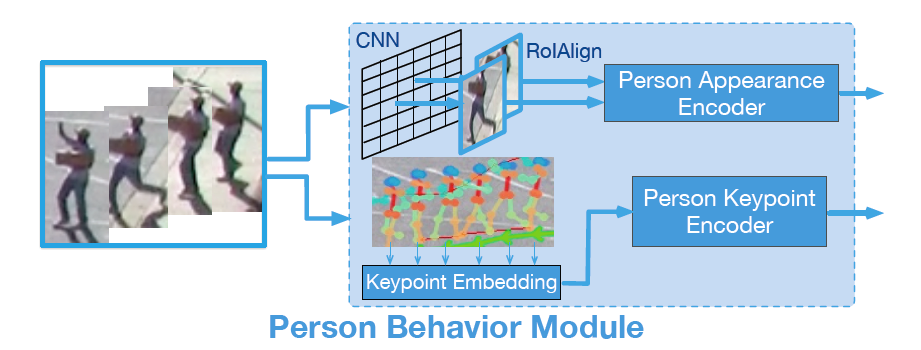
為了對人在場景中的變化進行建模,這裡用一個預訓練的帶有「RoAlign」的物體檢測模型,來提取每個人邊界框的固定尺寸 CNN 特徵。
而人物交互模塊負責查看人與周圍環境的交互,包含人與場景、人與對象的交互。
其中人與場景的交互是為了對人附近的場景進行編碼。
首先使用預訓練的場景分割模型導出每一幀的像素級場景語義分類,劃分出場景中的道路、人行道等部分。
將這些信息提供給模型,讓它能學習到人類的活動方式。比如一個人在人行道上比在草地上走得更頻繁,並且會傾向於避免撞到汽車。
軌跡生成器和活動預測
上面兩個模塊提取的 4 種特徵,包括場景、肢體動作、人與場景和人與對象關係等信息,由單獨的 LSTM 編碼器壓縮成視覺特徵張量 Q。
接下來使用 LSTM 解碼器直接解碼,在實際平面坐標上預測未來的軌跡。
這項研究用了一種焦點注意力的機制。它起初源於多模態推理,用於多張圖片的視覺問答。其關鍵之處是將多個特徵投射到相關空間中,在這個空間中,辨別特徵更容易被這種注意力機制捕獲。
焦點注意力對不同特徵的關係進行建模,並把它們匯總到一個低維向量中。
活動預測模塊有兩個任務,確定活動發生的地點和活動的類型。
相應地,它包含兩個部分,曼哈頓網格的活動位置預測和活動標籤預測。
活動標籤預測的作用是猜出畫面中的人最後的目的是什麼,預測未來某個瞬間的活動。活動標籤在某一時刻並不限於一種,比如一個人可以同時走路和攜帶物品。
而活動位置預測的功能,是為軌跡生成器糾錯。
軌跡生成器有個缺點,預測位置的誤差會隨著時間累計而增大,最終目的地會偏離實際位置。
為了克服這個缺點,就有了「活動位置預測」這項輔助任務。它確定人的最終目的地,以彌補軌跡生成器和活動標籤預測之間的偏差。包括位置分類和位置回歸兩個任務。
位置分類的目的是預測最終位置坐標所在的網格塊。位置回歸的目標是預測網格塊中心(圖中的藍點)與最終位置坐標(紅色箭頭的末端)的偏差。
添加回歸任務的原因是,它能提供比網格區域更精確的位置。
AI 只能預言人類 30 種行為模式
雖然模型設計中,考慮的非常周到,但面對現實情況時,仍舊會出現種種失敗案例:

左邊,預測人物要打開後備箱,但實際上是他只是站著。
右邊,預測任務將會向右前方前進,提著一些東西,但實際上他一直騎行,並向左前方拐彎,全然不顧前方即將到來的車輛。
從這些情況來看,模型應對一些場景還有些吃力。
此外,這個 AI 目前僅適用於美國國家標準局提供預定義的 30 個人類活動,例如關門、開門、關後備箱、開後備箱、提東西、打招呼、推、拉、騎自行車、跑、步行等等。
當然這項研究才剛剛開始,隨著研究的成熟,在自動化社會中,人類這一最不穩定的變量也就將會在控制之中。
如此,自動駕駛就能夠正式踏入人類的歷史舞台。
Source:arxiv
Text By Fortune Insight







